Surányi Gábor
Mihály:
OCCAM fordítóprogram készítése Prolog nyelven
(TDK dolgozat)
Konzulens:
dr. Iváncsy Szabolcs, Automatizálási Tanszék
Budapest, 1998.
Ezúton szeretnék köszönetet nyilvánítani:
Köszönetnyilvánítás *
Tartalomjegyzék *
1. Bevezetés *
1.1. Az occam programozási nyelvről *
1.2. A projektről röviden *
1.3. A Prolog programozási nyelvről *
2. A megvalósítás *
2.1. Termék definíció *
2.2. Projekt terv *
2.3. Követelmény specifikáció *
2.4. Felhasználói interfész *
2.5. Architekturális és részletes terv *
2.5.1. Az előfeldolgozó (preprocesszor) *
2.5.2. Az elemzőkről *
2.5.3. A JANUS2000 [13, 14] *
2.5.4. A J2000 Prologban elemzője (parser) [13, 15] *
2.5.5. A beépített elemző *
2.5.6. A kódoló *
2.5.6.1. Értékadás (’:=’) *
2.5.6.2. Kommunikáció (’?’, ’!’) *
2.5.6.3. Feltételes szerkezet (’IF’) *
2.5.6.4. Párhuzamos folyamatok (’PAR’) *
2.5.6.5. Alternatív folyamatok (’ALT’) *
2.5.6.6. Elemi adattípusok *
2.5.6.7. Időzítő (’TIMER’) *
2.5.6.8. Kifejezések *
2.5.6.9. További implementációs korlátok *
2.6. Tesztelés *
2.7. Értékelés *
3. További lehetőségek *
Irodalomjegyzék *
Napjainkban, ha egy szoftvertermék elkészítése a feladatunk, rendkívül sok és sokféle döntést kell meghoznunk. Ezek közé tartozik – sok mással együtt – az is, hogy milyen környezetre és milyen nyelven fejlesszünk. Az előbbit általában a feladat meghatározza, utóbbi esetében azonban nagyobb a szabadságunk: egy környezetben általában több nyelv is hozzáférhető.
Évtizedünk nagy divatja az objektum-orientáltság. Igaz, hogy a valóság megragadására könnyen és jól alkalmazható ez a szemléletmód, de a megvalósítása általában nagy futási idejű overheadet okoz. Emiatt mindig mérlegelnünk kell, melyik az a nyelv, amellyel a feladat egy adott szempontrendszer szerint a leghatékonyabban megoldható. Mint közismert, ha egy programot “egyszer” futtatnak, az egyszerű elkészítés, ha sokszor, akkor pedig vélhetően a sebesség a legfontosabb.
1.1. Az occam programozási nyelvről
Ez a nyelv rendkívül elterjedt – ha nem is az üzleti szoftverek világában.
Sok programozási feladat dekomponálható oly módon, hogy egyes részei teljesen vagy legalább a végrehajtás egy-egy szakaszában egymástól függetlenül fussanak. Az ilyen módon kialakított részek párhuzamosan futtathatóak. A párhuzamosíthatóságnak alapvetően két esetét különböztetjük meg: a pipeline processing-et és a data parallelismet. [11]
A párhuzamosság ill. annak látszata (kvázi-párhuzamosság) kétféleképpen biztosítható: szoftveres és hardveres úton. Ez utóbbi esetben szükség van azonban egy megfelelő nyelvre, ami a hardver ilyen irányú képességeit kihasználja.
A transzputer ilyen többfeladatos működésre képes hardver. (A felépítéséről részletesebben olvashatunk például az irodalomjegyzékben 12. sorszámmal feltüntetett könyvben.) Több transzputer összekapcsolásával pedig további, immár valódi párhuzamosságot vihetünk a rendszerbe.
Sok programozási nyelv létezik, amely konkurens működés leírását teszi lehetővé. Ezek közül most az összehasonlítás kedvéért csak háromról írnék ([9]).
A Linda az egyes egységek nemszinkron kommunikációját teszi lehetővé az ún. tuplespace-n (TS) keresztül.
Az ADA szinkron kommunikációt valósít meg: az adatcserét folytatni kívánó folyamatoknak az adatátvitel idejére randevúzniuk kell. Egy-egy ilyen randevú során kétirányú adatcsere folyhat. Az azonosítás egyoldalú, csak az egyik félnek kell pontosan ismernie (megneveznie) a másikat az összeköttetéshez.
Az occamet – szemben a fenti két nyelvvel – kifejezetten egy bizonyos hardver, a transzputer számára találták ki. A közvetlen gépi utasításokra fordíthatóság megkönnyítése miatt rendkívül egyszerű, ugyanakkor elegendően magasszintű nyelv. Az adatstruktúrák konkrét elhelyezkedésével – ellentétben például az assemblyvel – nem kell foglalkoznunk, és hatékony vezérlési szerkezeteket is találunk benne (Pl. ALT). Szintén szinkron átvitelt tesz lehetővé az egyes folyamatok között, azonban egy ilyen ún. csatornán csak egyetlen irányban. A csatornát mindkét félnek meg kell neveznie. A fordító gondoskodik arról, hogy egy csatorna pontosan két folyamat között jöjjön létre, és az egyik csak adjon rá, a másik csak vegyen róla. Ha egy csatorna azonos processzoron futó két egység közötti, akkor memóriamásolással, ha pedig különböző CPU-kon futnak, akkor hardver linkeken keresztül valósul meg.
A transzputerek néhány tipikusnak tekinthető és érdekes alkalmazásáról (multimédiaadat-feldolgozás, modellezés és szimuláció, irányítástechnika, adatbázisok) az irodalomjegyzék 10. sorszámú könyve szól.
A gyakorlati megvalósításokban az occammel olyan célrendszereket programozunk, amelyek operációs rendszer nélküliek és (igen gyakran) több processzort is tartalmaznak. Ezekből két dolog is adódik:
Mindkét probléma megoldásához jelentős segítséget nyújthat, ha a fejlesztési környezetben biztosítunk minél jobb és teljesebb lehetőséget szoftverek futtatására.
A TDK témájának ötlete akkor merült fel, amikor Mérés Laboratórium III. című tárgyam során a tanszéken megtalálható, egy IBM PC kártyán helyet kapott transzputert programoztam: meglehetősen nehézkes volt a parancssor használata a nyelvvel való ismerkedés során, ugyanakkor mivel a fordítóprogram is a transzputeren futott, lehetetlen volt az eszköz nélkül fejleszteni.
A későbbiekben részleteiben is ismertetendő szoftver az x86 alapú Win32 platformot készíti fel occam nyelven íródott programok futtatására: egy fordítóprogram. A platform kiválasztásában fontos szerepet játszott elterjedtsége, skálázhatósága, valamint az, hogy a folyamatok közötti kommunikációs és szinkronizációs lehetőségei fejlettek. Annak oka, hogy a Win32 környezetben csak Intel alapú számítógépekre készül a szoftver, a választott programozási nyelv felhasznált implementációja, ami más hardveren, ahol a Win32 elérhető, nem létezik. (Vö. a következő pont.)
Az Interneten is több termék ill. termékleírás elérhető, amely transzputertől független occam programozást és kipróbálást tesz lehetővé. (Például: Kent Retargetable Occam Compiler, http://NSCP01.PHYSICS.UPENN.EDU/parallel/occam /projects/occam-for-all/kroc/) Ezek azonban vagy egyetlen CPU-n saját “mikrokerneljük” segítségével valósítják meg a konkurenciát, vagy eleve több processzoron (lazán csatolt rendszerek) futnak. Meg sem kísérlik, hogy valami másféle konkurenciát ([10], nem dedikált, hanem pl. OS által megvalósított) lehetővé tegyenek. Másrészt ezek a projektek elsősorban nem az occambeli fejlesztés további támogatását tűzték ki célul. Pedig mint azt lejjebb, a továbbfejlesztési lehetőségekben leírom, a Prolog közvetlen alkalmazása, mint implementációs nyelv, a későbbiekben igen hasznosnak bizonyulhat.
1.3. A Prolog programozási nyelvről
A Prolog, mint neve is mutatja (PROgramming in LOGic) a logikai programozás egyik és egyébként legelterjedtebb megvalósítása. A logikai programozás alapgondolata az, hogy egy a logikán alapuló nyelvet használjunk programozási nyelvként; végrehajtási módszerként pedig logikai következtetési ill. tételbizonyítási eszközöket használjunk. Így egy olyan nyelvet kapunk, amely korunk követelményének megfelelően igen absztrakt [7], lehetővé teszi a “WHAT rather than HOW” jellegű programozást. [4]
A Prologot tulajdonságai miatt ma is elterjedten alkalmazzák (a LISP mellett) a mesterségesintelligencia-kutatásokban.
A szoftver megvalósításához a Svéd Számítástechnikai Intézet Prolog implementációját (SICStus Prolog) használtam. Ez UNIX-okra és IBM PC alapú gépeken többféle operációs rendszer alá érhető el. Ahhoz, hogy C nyelvű forrásokkal együtt futtatható programot lehessen előállítani, Win32-es RunTime támogatását is igénybe vettem.
Aki valamennyire is ismeri a Prologot, tudja, jól alkalmazható elemzési feladatok (amire például a fordítóprogramoknál szükség van) nemdeterminisztikus megoldására. A projekt célja egyben annak megvizsgálása is volt, mennyire egyeztethető ez össze a hibajelzés megvalósításával. Bővebben erről később, az implementációról szóló részben írok.
A következőkben egy hagyományos szoftverfejlesztési technológia ([7]) egyes lépéseinek néhány fontosabb momentumát emelem ki. Nyilvánvalóan nem térhetek ki minden egyes és ráadásul a téma szempontjából kevésbé érdekes részletre, hiszen az a dolgozat keretét jócskán kimerítené, továbbá annak lényegét is elfedné. (Mi több, egy teljes dokumentáció így egyben a nagymértékű redundancia miatt kevésbé lenne olvasmányos.) Ennek megfelelően igyekeztem a téma szempontjából fontosabb részekre koncentrálni, illetve a valamilyen szempontból a szokásostól eltérő, újszerű dolgoknak kellő figyelmet és helyet szentelni.
A kitűzött feladat egy occam 2 fordítóprogram létrehozása. Kimenete C++ nyelvű forrás, amit a használó a rendelkezésre álló natív compilerével fordít futtathatóra. Ehhez felhasználja az általam biztosított futási idejű függvénykönyvtárat is. Futási környezet mind fejlesztéskor (a fordítóprogram előállításakor és használatakor), mind a lefordított felhasználói program verifikációja során az Intel alapú Win32 console subsystem Windows NT alatti realizációja. (A szoftver kifejezetten Windows NT alá készült, mert a Windows9x a Win32 API-t nem valósítja meg teljesen.)
A dolgozatom címe abban az értelemben nem teljes, hogy nem csak Prolog kódot írtam. A szoftver bizonyos részei, például az, ami a felhasználóval való kapcsolattartásért felelős és a többiek működését koordinálja, C/C++-ban íródott. Azonban a lényegi és legnagyobb része, az elemző és a kódgenerátor Prologban készült. Mindezek mellett – mint az a termékdefinícióból is kiderül – szükségszerűen a futási idejű támogatás is C/C++-ban valósult meg.
A C/C++ fejlesztőeszközként a Microsoft Visual C++ 5.0 SP3-t használtam. Még a fordítóprogram forrásának hordozhatóvá tétele nem történt meg, ezért más gyártók termékére való portolással problémák lehetnek.
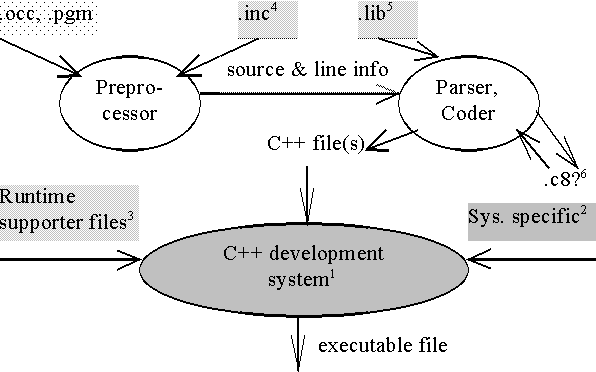
A program adatokkal való kapcsolatát az 1. ábra mutatja.
1. Ábra: A fordítás nulladik szintű adatfolyam-diagramja
Jelmagyarázat: (a kiterjesztések az INMOS-féle rendszerből származnak, [12])
Ennek megfelelően a programozó elkészíti a programjának forrását egy tetszőleges editorral, ami legalább egy PGM kiterjesztésű fájlból áll. Ez a főprogram. Ebben a #USE direktíva segítségével hivatkozhat a többi forrásfájlra. Ekkor a program a megfelelő C8? kiterjesztésű fájl(oka)t használja fel, ami(ke)t előzőleg az OCC kiterjesztésű fájl(ok)ból állított elő. A programozó a futási idejű támogatást ugyanezzel a direktívával veheti igénybe (*.LIB). Az #INCLUDE-olható *.INC fájlok az occam számára tartalmaznak rendszerkonstansokat.
A program a különböző fordítási módokat (stop, halt, undefined), amik az érvénytelen (invalid) processzek viselkedését szabják meg, nem támogatja. A *.C8? fájlok keresésekor *.C8U, *.C8S, *.C8H sorrendben próbálkozik, de ő maga csak *.C8U-kat készít.
A fordítóprogramtól kapott C++ forrásokat és az occam runtime-ot lefordítva, majd a C/C++ könyvtárakkal összeszerkesztve áll elő a futtatható fájl. Az occam futási idejű támogatását forrásban adom közre, mert a különböző C/C++ környezetek object- és libraryfájl-formátumai nem kompatibilisek egymással. Természetesen, ha a programozó gyakran készít ugyanabban a C/C++ környezetben occam programokat, érdemes a runtime forrásait külön lefordítania, és csak szerkesztéskor a megfelelő fájlokat a többihez (a midig változókhoz) hozzáadnia.
A felhasználó a szoftvert az occomp.exe-vel indítja megfelelő parancssori paraméterekkel. A parancssorban fájlnevek és kapcsolók lehetnek, amiket szóközök választanak el egymástól. Az idézőjelek (’"’) között szereplő karaktersorozatokban szóközök is szerepelhetnek. A kapcsolók csak az utánuk szereplő fájlokra fejtik ki hatásukat. A program kapcsolóként értelmez minden mínusz- (’–’) jellel kezdődő sztringet, kivéve egy önmagában álló ’--’ sorozat után, amikor is fájlnévnek tekinti őket. Ezzel lehetőség nyílik mínusszal kezdődő fájlok használatára is. A kapcsoló neve a kettőspont (’:’) karakterig terjed, értéke pedig a kettőspont után kezdődik.
A program üzenetei angol nyelvűek. Ezek többsége átirányítható fájlba vagy átadható egy másik programnak. Kivételt képeznek a hibaüzenetek, azok mindenképpen konzolra íródnak.
A program futása a Ctrl+C billentyűkkel bármikor megszakítható.
A fordító a szükséges kiegészítő *.INC és *.LIB fájlokat (az aktuális mappa után) az ún. library-könyvtárban is keresi. Ennek megadására két lehetőség van:
Mindkét esetben több elérési utat is specifikálhatunk pontosvesszővel (’;’) elválasztva, ezekben a keresés a megadott sorrendű. A parancssori mappákban a program előbb keres, mint az OCCAMLIB-nél előírtakban.
Még egy megjegyzés: a *.PGM fájl által igényelt *.C8? fájloknak már létezniük kell (és az sem árt, ha aktuálisak), ezért az *.OCC fájlokat a parancssorban előrébb szerepeltessük, mint a főprogramot, mivel a fordítás a paraméterezési sorrendnek megfelelően történik.
Ha a programot a kérdőjel (’?’) kapcsolóval indítjuk, egy rövid, összes kapcsolóját tartalmazó segítő szöveget ír ki.
2.5. Architekturális és részletes terv
A programfordítás legalább kettő, jól elkülöníthető fázisra bontható:
Ezek szétválasztása nem követelmény, de nélkülük a program eléggé ad hoc jellegűnek fog tetszeni: kissé bonyolultabb forrásnyelv esetén a fordítóprogram forrása kaotikus lesz. A két rész között egy speciális adatstruktúra adja a kapcsolatot: fa. Ez tehát adatstruktúra-orientált szemlélet.
Az elemzés során kapott fa a forrás szerkezetét tükrözi. A mesterséges (program-)nyelvekre jellemző, hogy miden részének pontosan definiálható hatásköre van: a fa alá- és fölérendeltsége pontosan ezt fejezi ki. Egy legfelső szintű iteráció egy fiktív csomópont felvételével faszerűvé alakítható.
2.5.1. Az előfeldolgozó (preprocesszor)
Mint az az előző pontból is kitűnik, az előfeldolgozó nem különösebben hangsúlyos része egy fordítóprogramnak – ott fel sem tüntettem.
Az a technika, hogy az elemzés és kódolás előtt egy, jobb esetben külön vezérelhető előfeldolgozó végez különböző, szigorúan a forrásszövegre korlátozódó módosításokat, igen jól használható, mint azt a C nyelv óta mindannyian tudjuk. Ez egyfajta flexibilitást ad a programozó kezébe, és könnyen ki is terjeszthető abban az értelemben, hogy további feladatok megoldására is felkészíthető.
Jelen esetben egy preprocesszor használata nem csak elegancia, hanem szinte kötelesség. Az occam a sor elején meglehetősen sok, méghozzá jól meghatározott számú szóközt tartalmazhat. A legtöbb szerkesztőprogram ezekből bizonyos számút tabulátorokra cserél. Ezeket viszont a fordító további része szóközökként szeretné látni, így az esetleges tabulátorokat ez a megvalósítás 8 szóközre (ez a leggyakoribb) cseréli az előfeldolgozás során. (Természetesen a pontos szám nem kellene, hogy feltétlenül rögzített legyen, akár a parancssori kapcsolókkal történő beállítás is szóba jöhetne. Ekkor a 8 alapértelmezett érték lehetne.)
A fenti cserén kívül itt oldottam meg az #INCLUDE-olást. Ez a funkciójának megfelelően forrásszöveget másol be az adott helyre.
A jelenlegi változat az elemzőnek átadott szöveget a ’forrásnév.pre’ fájlban megőrzi, az hibakeresési céllal tanulmányozható.
Az elemzést általában szintén két lépésben valósítják meg:
Az előbbi az egyes szavakat ismeri fel a forrásban, a betűsorozatot szósorozattá konvertálja. Az utóbbi pedig a kapott szósorozatot próbálja meg a programnyelv jól definiált, ismert szintaxisa alapján feldolgozni.
Mindkettő megvalósítására létezik kitaposott út. A lexikai elemzést egyszerű állapotgéppel megvalósíthatjuk. Mivel minden programnyelv determinisztikus és környezetfüggetlen, készíthető hozzá LR(1) szintaktikus elemző. [6]
Az elemzők elkészítésére a UNIX világból eredően ma már szinte minden platformra elérhető a lex és a yacc megfelelő változata, amik a fenti problémát generálisan oldják meg: a megadott szintaxisnak megfelelően generálnak egy-egy, általában C nyelvű forrást, ami majd elemzi a szöveget. Azonban így is van még egy probléma: az occam a sor eleji szóközöket használja a blokkhatárok jelzésére. Ennek direkt bevitele az elemzőbe szinte reménytelen vállalkozás.
Alternatív megoldásként kínálkozik a Prolog visszalépéses, mintaillesztéses eljáráshívás-szervezése. Ekkor általában a beépített DCG nyelvtan (ismertetője megtalálható pl. az irodalomjegyzék 4. számú könyvében) segítségével leírjuk a forrás szintaxisát és a többi már a rendszer dolga. Ezzel két apróbb probléma is van: egyik az idő, a másik a hibajelzés. A teljes keresés, (amit a Prolog, ha racionalizálva is, de elvégez,) sok időbe telik/telhet. Természetesen a fordítóprogramot arra szeretnénk használni, hogy programunkat lefordítsa, de addig, míg ez sikerül, hányszor kell a szintaktikusan rossz forrásunkat visszautasítania! Az esetleges hibaüzenetek előállítása ugyanakkor ezzel a módszerrel még nem megoldott. Ha – mondjuk – az a feladatunk, hogy többségében jó források szintaktikai helyességét ellenőrizzük, egy ilyen elemző megvalósítása egyszerű, mivel a forrásnyelv szintaxisleírása általában könnyen alakítható DCG-vé. (Hogy egy fastruktúrát is visszaadjon, tehát ne csak vizsgálatra használhassuk, már kicsit több időnkbe és munkánkba kerül.) Persze, abban a kevés esetben, amikor hibás a forrás, vakarhatjuk a fejünket, vagy odaadhatjuk egy kicsit költségigényesebb fordítónak, hogy mondja meg mi is a hiba. Most azonban egy teljes fordítóprogramról van szó, tehát ez az út nagyon göröngyös, nehezen járható. Vegyünk akkor igénybe egy hibajelzést is támogató, Prolog nyelvű, könnyen bővíthető, generális eszközt!
A JANUS2000 fejlesztőcsomag már elkészült, de forrásban adott szoftverek módosítására alkalmas. Eredetileg a 2000. évvel kapcsolatos problémák megoldására fejlesztették ki a Digital Equipment Magyarország Kft-nél (1124 Budapest, Németvölgyi út 97.), de jól alkalmazható más területeken is, ha az alább ismertetendő részei erre megfelelőek.
Három, jól elkülöníthető része van:
Az első része (parser) egy adott leírású szintaxis alapján a forrásból fát épít. A Y2KPRN az elkészült fát járja be, és minden egyes csúcsára egy adott script nyelven specifikált feladatokat hajt végre. Ilyenek lehetnek például automatikus módosítások, megjelölések (címkézések) stb. A módosított fát aztán kézzel, a kinyert adatokat használva módosíthatjuk (ezt segíti pl. az ACODE), avagy a Y2KCONV segítségével állományba is írhatjuk. Ezzel az újrafordításra is lehetőség nyílik.
Az eredeti termék imperatív programozási nyelven (C++) készült el annak minden hátrányával együtt. Az idén az IQSoft Rt-nél megkezdődött ennek áttétele Prologba. Ez a szoftver nagyobb rugalmasságát és a forrás jobb átláthatóságát eredményezi.
2.5.4. A J2000 Prologban elemzője (parser) [13, 15]
Az eredeti megvalósítással megegyezően itt az elemzés egyetlen lépcsőben történik. A program mind a tokenizálást, mind a faépítést ugyanazon szintaxisleírás alapján végzi.
Az elemzés a szintaxisleírás beolvasásával kezdődik. Ezt egy közbülső alakra konvertálja, amit majd a forrás elemzésekor egy interpreter fog felhasználni. Az interpreteres feldolgozás jelentős sebességcsökkenéssel jár, de egy közvetlen Prolog forrás előállítása nehezebb lenne. Mindenesetre mivel a mostani ilyen módon igen lassú, várhatóan el fog készülni a közvetlenül Prolog forrást előállító változat is.
Ezek után az interpreter egy speciális szimbólummal (’Start’) megkezdi a forrás értelmezését. Ennek végeztével a fa lista formájú változata (szimbólumnév, kezdőpozíció, végpozíció a fájlban, mélység a fában) egy kimeneti állományba kerül.
Az elemző a fában nem minden szimbólumot tüntet fel, az ún. Z-szabályokat kihagyja, azok alatti részfát a szülőhöz tartozónak tekinti. (Z-szabályok azok, amik neve nagy ’Z’ betűvel kezdődik.) Ezzel elkerülhető, hogy feleslegesen nagy fát kapjunk vissza. Ha egy Z-szabály szülője szintén Z-szabály, akkor annak szülőjébe kerül a részfa, sít. Végül is (a csak elméleti szempontból lényeges) szélsőséges esetben a ’Start’ alá kerül egyetlen elemként az egész forrás.
Léteznek beépített szabályok is. Ezek egy része az elemzőt vezérli, másik részük az elemző használatát könnyíti meg. Az utóbbiak közé tartozik például: a ’bsymbol’, a ’number’.
Programnyelvekben gyakori, hogy a forrás(ok)ban vannak bizonyos karakterek ill. –sorozatok, amelyeket át kell lépni (sehol sem kell feltüntetni). Ezek gyakran szóköz és megjegyzés jellegű részek. Ezeket az elemző automatikusan kivágja, ha egy speciális, ’ZSKIP’ nevű szabályban leírjuk. Ebben természetesen további nemterminális szimbólumra is hivatkozhatunk. Ha az nem Z-szabály, akkor sem kerül a kimenetbe. A ’ZSKIP’ alkalmazását az interpreter automatikusan megkísérli minden szabály előtt. Ennek egy részfára ill. visszaállításig (’ZSkipOn’) tartó kikapcsolására szolgál a ’ZSkipOff’ terminális.
A program készítői az egyszerű megvalósításhoz felhasználták a DCG-jelölés egy generalizációját (EDCG), amellyel több, általánosabb viselkedésű láncargumentum használható rejtett módon. (A szerző kezéből származó teljes leírás elérhetőségét az irodalomjegyzék 8. pontja tartalmazza.)
Ugyan a tervezőjének szándéka szerint a fentebb ismertetett megoldás eléggé rugalmas, hogy megfelelő szintaxissal bármely programnyelven készült forrást elemezhessünk, a valóság korántsem ez. Az occam például a szóközt másként kezeli sor elején és máshol. Elöl a megfelelő blokkba tartozást jelzi, később pedig átlátszó karakter. Ráadásul a blokk-kezdetet (két szóközzel beljebb) ill. blokkvéget (kettővel kijjebb) is meg kell tudni adnunk a szintaxisleírásban, továbbá ezt megfelelően kezelnie is kell az elemzőnek.
Alapja a fentebb ismertetett Prolog parser, az eltéréseket itt ismertetem.
Az occamhez igazítást a következő elven oldottam meg: létezik egy belső változó (indent), ami azt mutatja, mennyi az aktuális bekezdés. Ezt tudjuk állítani (beljebb: ’ZIndentOne’, az aktuális oszlopra: ’ZSetIndentPos’ és vissza a szabály elemzésének kezdetekor fennállt értékére: ’ZRestoreIndent’), valamint egy terminálissal (’ZPassIndent’) arra tudjuk rábírni, hogy az az aktuális pozíciótól az indent változó értékéig szóközöket várjon az inputon.
A fa gyökérszimbólumának neve ’StartOCC’ ill. ’StartPGM’ attól függően, hogy milyen típusú (kiterjesztésű) fájlt dolgoz fel éppen.
Sajnálatos módon az eredeti elemző beépített név- és számterminálisai nem alkalmazhatóak, mert az occam nevekben pontok (’.’) is előfordulhatnak, a számok pedig lebegőpontosak is lehetnek. Ezeket külön-külön ’ZSkip*’-okkal keretezve kellett definiálni, ezzel is tovább csökkentve az amúgy sem túl nagy elemzési sebességet. Ugyanakkor itt már a ’ZSkip*’ szabályok hatóköre nem részfára, hanem az ellentétes értelmű szabályig terjed ki. (Természetesen ’ZSKIP’-ben hatástalanok.)
A terminálisokról szólva, bár nem különösebben lényeges, de a teljességhez hozzátartozik, hogy egy ’Zeof’ nevűt is felvettem.
A beépített szintaxisleírás közbülső (interpreter-)kódként szerepel a programban (ez nem változik, nem kell újrafordítani), de még nem teljes: a sortörést, ami például operátorok után ill. sztringkonstansok belsejében lehet, még nem ismeri.
A fa visszaadása itt egy Prolog változóban történik, amely tartalmazza a szimbólum nevét, a kezdő és a végző sor-oszlop párokat, valamint a gyermek fákat, ha van akár egy is. Ha nincs, (azaz lejjebb nincs nem Z-szabály,) akkor egy struktúrában a forrás megfelelő darabját tartalmazza.
A forrás hibáinak felismerése és kijelzése a következőképpen történik: az elemző mindig megjegyzi, melyik az a legnagyobb sor-oszlop pozíció, ameddig eljutott. Sikertelenség miatti visszalépéskor, ha később jó utat talál, annál tovább fog jutni, ha pedig a forrás hibás, egész a kezdetekig visszalép. Így tehát az elemzés az első hibán nem jut túl, még akkor sem, ha a hiba javítható volna (pl.: kettőspontot vár). Mivel minden programozási nyelv egyértelmű, így az occam is, a fenti mutató tehát ily módon a hiba helyét fogja megadni.
Ezzel szemben a helyzet egy aprócska, ám annál nagyobb hatású racionalizálás miatt nem ilyen kellemes. Azért, hogy az elemzés kicsit felgyorsuljon, egy szabály sikeres alkalmazása után az interpreter a többi (, az alkalmazott szabállyal azonos szintű és közös szülőjű) alternatív szabály alkalmazását későbbi visszalépés után sem próbálja meg (cut-ot alkalmaz). Ennek az a következménye, hogy ha valamely programrészlet prefixuma lehet egy másiknak, akkor az előbbit az utóbbinak meg kell előznie az adott közös szülő szintaxisleírásában, különben hibát fog jelezni. Például: operandus és operandus + operandus.
Hiba esetén a logikai sorszámokból a megfelelő fájl kijelölése és a fizikai sorszám előállítása, valamint az üzenetek megjelenítése a keretprogram feladata. A hibaüzenet egyébként annak az egy vagy több szimbólumnak a nevét tartalmazza, ami a forrásban következhetett volna. A Prologos implementáció kitűnő bővítési lehetőséget kínál. Elérhető, hogy az egyes szimbólumokhoz egyedi hibaszöveget rendeljünk és ezzel az alapértelmezett kijelzést egyszerűen, könnyen és szépen megváltoztathassuk.
Végezetül felsorolom az elemző egyes moduljait funkciójukkal együtt:
| modulnév | funkció |
| defrules.pl | az interpreter |
| grammar.pl | occam szintaxis interpreter formában |
| io.pl | forrás beolvasása, üzenetek kiírása |
| parser.pl | a főprogram |
| terminal.pl | beépített terminálisok definíciója |
A fordítóprogram legvaskosabb és legfontosabb részét a kódoló alkotja, ami az elemző által adott fát C++ forrássá próbálja átalakítani. Ez természetesen nem sikerülhet, ha a forrás hibás, például nem deklarált változóra hivatkozunk. Minden ilyen esetben az elemzőhöz hasonlóan jelzi ki a hiba helyét és pontosabb okát. Ehhez most azt használja fel, hogy a fában megkapta minden egyes (feltüntetett) egység kezdetét és végét sor-oszlop pozícióban. Ha a hiba jellege miatt a fordítás (egyszerűen) nem folytatható, akkor leáll; különben a hiba kijelzése után a feldolgozás folytatódik.
A kódolási menet először egy általános fejlécet ír ki az output állományba. Ez – a fordítóprogramra vonatkozó információkon kívül – tartalmazza az occam forrás nevét, módosításának időpontját, továbbá a C++ fordításhoz szükséges sorokat (vezérlősorok, #include-ok).
Ezek után inicializálja belső változóit és hozzákezd a fa gyökerének fordításához (’tree2cpp’). PGM fájlban a legkülső szinten az induló kód is megtalálható (nem csak különféle definíciók), ezt egy ’occmain’ nevű függvénybe teszi.
A fordítás során a kód kétféleképpen kerülhet a kimeneti állományba. Az általános eset az, hogy a ’tree2cpp’ egyik kimeneti változója egy tetszőleges mélységben egymásba skatulyázott lista, amelynek legalsóbb szintjein atomok találhatóak. Annak oka, hogy a lista többszintű (nem egyszerű), hatékonysági. Sokkal időigényesebb lett volna annak egyes darabjait egymás után fűzni. A választott megoldás viszont könnyen realizálható és a kiírás nem sokkal bonyolultabb. Az atomokat a lista mélységi bejárásával közvetlenül egymás mellé írva teszem az output folyamba.
A másik esetben a megfelelő függvények közvetlenül nyomtatják ki a forrás egy-egy részletét. Erre például akkor van szükség, amikor egy új függvényt definiálunk, hiszen a C(++) nem ismeri az egymásba skatulyázott függvénydefiníciókat szemben az occammel vagy például a Pascallal. Ezzel együtt ugye elveszítjük a függvények láthatósági hierarchiáját is. Tehát elméletileg minden szintű függvény látható lesz bármely másik által a C++ forrásbeli helyzetének megfelelően. Mivel létezhetnek egymással azonos nevű occam függvények, amelyek nem ütköznek, ugyanakkor ezek C++ megfelelői ütközhetnek, célszerűnek látszik minden függvénynévhez hozzátenni valami egyedit. A megvalósításban ezt a feladatot egy szigorúan monoton növekvő sorszám látja el.
A figyelmes olvasónak feltűnhet, hogy a több helyről való felhasználhatóság biztosítása végett a lefordított függvényeknek C++-ban globálisaknak kell lenniük. Ez ugyanakkor több hiba forrása lehet. Először is lehetséges, hogy elvileg nem látható függvényt elérjünk (hiszen C++-ban globális, nem fájlra lokális). Más fájllal szemben védekezhetnék a nem fájl láthatóságú occam függvények megfelelőinek ’static’ kulcsszóval ellátásával. Ehhez azonban újabb változót kellene bevezetni és megfelelően kezelni, így ettől a jelenlegi változatban (némi lelkiismeret-furdalással, de) eltekintettem. Ráadásul ez nem nyújtana védelmet ugyanazon fájlban szereplő függvények ellen. Ez utóbbi megoldása praktikusan lehetetlen, hiszen csak a C++ forrás feldarabolásával lenne lehetséges.
Másodszor az alkalmazott megvalósításban az is előfordulhat, hogy két különböző (C++) modul függvényei a szerkesztéskor összeütköznek. Ha csak a fájl szintű függvényeket láthatnánk kívülről, akkor egy ilyen ütközés feltétlenül hibát jelentene. Ugyanakkor mivel az occam függvénynevek megfelelőit számokkal toldottam meg, nem is minden ütközés kerül napvilágra, mert bár az occam nevek azonosak, de a C++-os kiegészített nevek már nem feltétlenül. Erre gyógyírként az occam® C++ névtranszformációs táblázat explicit végigbogarászása szolgálhatna. Ekkor a tényleges ütközést már csak attól kellene megkülönböztetnünk, amikor egy alacsonyabb szintű függvény elfed egy magasabb szintűt, ami bármikor lehetséges és legális. Ez sem lehetetlen, de megvalósítása túlzottan nagy gyakorlati előnyökkel nem járna, így most ezt sem építettem be.
A fentiekben említett sorszám suffixet alkalmaztam továbbá típusokra és változókra is. Az utóbbi esetében úgy tűnik, hogy pusztán magánszorgalom, afféle “biztos, ami biztos” alapon történt; az előbbinél pedig a problémák élesben is jelentkezhetnének, amikor a több értéket visszaadó occam függvényeket fordítom. Ekkor ugyanis a C++-ban egy struktúrát adok vissza. Minden további nélkül elképzelhető két occam függvény, amely ugyanolyan típusú értékeket ugyanolyan sorrendben ad vissza. A második ilyen függvény fordításakor vagy ellenőriznem kéne, volt-e már ugyanolyan struktúra definíció, vagy (mint ahogy én is teszem) meg kell különböztetni valahogyan a két példányt. Ez – bár rendkívül szószátyár megoldás, – de egy további előnnyel is jár: a kimeneti forrásban egyszerűen rákeresve a C++ típusnévre megtalálható az összes használata, ugyanakkor a C/C++ fordítónak csak fordítási és szerkesztési időben jelent többletmunkát, a végleges futtatható állomány nem lesz nagyobb.
A fordítás során rekurzió a fa csomópontjainak megfelelően annak mélységében történik. Ezek során három adatstruktúra rekurzív. Az egyik a “típusokat” tárolja (occam név, C++ név, leírás), a másik a “változókat” (occam név, C++ név, tartalom), a harmadik pedig az occam nyelvnek megfelelően aktuálisan elérhetetlen entitásokat. Az első két adatstruktúra tartalmának megnevezése azért szerepel idézőjelek között, mert azokat megfelelően tágan kell érteni. Például a típusoknál tárolódnak a protokollok definíciói, a változóknál pedig a függvénydeklarációk. Az adatstruktúrák reprezentációiról csak annyit, hogy listák, mert könnyen kezelhetőek és például hozzáadáskor nem kell egyetlen részét sem újraépíteni.
Az aktuálisan nem elérhető entitások közé tartoznak például azok a változók, amik egy parallel szerkezet egy másik ágában értéket kaptak, illetve rövidítésben (abbreviation) szerepeltek vagy típusukat explicit felülbíráltuk (retype). (Csatornák esetén a használat iránya, tömbök esetén pedig a kiterjedés is fontos a használat módján (olvasás vagy írás) kívül.) A nem elérhető “változókat” tároló adatstruktúrának van egy, a többiektől eltérő tulajdonsága: a megfelelő programszerkezetekben a fa szomszédos csúcsaiban akkumulátorként funkcionál. Természetes ábrázolási formája a halmaz. Minden, valamely változóra hivatkozó részfa feldolgozásának befejezésekor egy visszatérési érték azt adja meg, hogy melyek azok a változók, amelyeket a részfa használt és felsőbb egységben lettek definiálva. (Ez például eljárás- és függvénydefinícióknál a szabad változókat jelenti, és – mivel C++-ban nincsenek egymásba skatulyázott függvénydefiníciók – ezeket fordítási időben fel kell oldani, elérhetővé kell tenni.) Így lehetővé válik annak adminisztrációja, hogy mely változókat nem érhetnek el más processzek illetve mely változókra nem hivatkozott a forrás sehol sem. Ez utóbbiakra a fordító figyelmeztetést ír ki.
Most pedig a főbb koncepciók ismertetése után rátérek néhány olyan részletre, amely már közvetlenül a megvalósításhoz kapcsolódik és nem triviális.
Itt három dologra kell tekintettel lenni:
Az első két esetben megoldásként kétlépéses értékadást alkalmaztam. Előbb egy ideiglenes változóba teszem az értéket, majd onnan a célterületre. Tömbök esetén pedig másolást kell előírni, hiszen egy egyszerű C/C++ értékadásnál (’=’) csak mutatóművelet történik.
2.5.6.2. Kommunikáció (’?’, ’!’)
A processzek közötti adatátvitel ’channel’ nevű objektumok segítségével történik. Ez az osztály az occam runtime része, szemaforos szinkronizációval működik. A tag-es protokollok tag-jei felsorolási (’enum’) típusúak. A hossz átvitele a hossz típusának (’INT’) megfelelő típusként történik.
2.5.6.3. Feltételes szerkezet (’IF’)
A feltételes szerkezetek fordításakor több problémát is meg kell oldani:
A generált kód magja egy megfelelő mélységben egymásba fonódó ’if’-’else’ utasítás. Az ’if’ utáni feltétel teljesülése esetén a megfelelő ’if’ ág lefordítottja hajtódik végre, különben az ’else’ után próbálkozik a következővel. Végül – ha nem volt igaz feltétel – egy üres utasítás (’;’) hajtódik végre.
Minden legkülső szintű feltételes szerkezetnél definiálok egy indikátort, amit hamisként inicializálok. Ez fogja jelezni, valamely feltétel teljesült-e, mert akkor annak törzsében igazra állítom. Egymásba ágyazott esetben az indikátorváltozó közös, a külső szinten feltételként azt vizsgálom, egy alsóbb sikerült-e.
Iteratív esetben (replicated) létrehozok egy ciklust, amelynek egyik bennmaradási feltétele az indikátor hamis értéke. A ciklus törzsében pedig a (nyilván az iterációs változóra is hivatkozó) feltétel értékét az indikátorba másolom. Ha értéke igaz, a törzs végrehajtása is megtörténik.
2.5.6.4. Párhuzamos folyamatok (’PAR’)
A párhuzamos folyamatok kezelését a runtime ’parallel’ modulja végzi. A ’PLACED PAR’ utasítások a célnak (nem dedikált párhuzamosság) megfelelően ’PAR’-ral azonos kóddá fordulnak. A párhuzamosan futtatandó processzek mindegyike egy-egy önálló threadként jelenik meg az operációs rendszer számára. (A változóval többszörözött (replicated) párhuzamos szerkezetek esetén is, de a kód azonos, viszont egyetlen változóban (az indexben) eltérő változókészletet kapnak.) A threadeket az OS saját hatáskörében ütemezi. Mivel a processzek által közösen használható adatok meglehetősen le vannak szűkítve (pl. csatorna különböző végei, csak olvasott változók stb.), ezért egy jó ütemezővel és több processzorral felvértezett számítógép esetén előadódhat olyan helyzet, hogy az egyes folyamatok időben tényleg konkurensen futnak. Amíg a szülő összes ’PAR’-beli processze be nem fejeződik, a szülő ’WaitForMultipleObjects’-cel várakozik. Ez lehetővé teszi az operációs rendszer ütemezője számára, hogy a várakozó szálakat hatékonyan alvó állapotba helyezze, és az erőforrásokat (elsősorban a CPU-(ka)t) a gyermekek számára hozzáférhetővé tegye.
2.5.6.5. Alternatív folyamatok (’ALT’)
Az alternatív folyamatok megvalósításánál ugyanazokkal a nehézségekkel találkozunk, mint az ’IF’-es szerkezeteknél. (Lásd ott!) Ezért aztán a megoldás is hasonlít az ott leírtra.
Először is felveszek egy logikai változót, ami azt fogja jelezni, valamelyik ág lefutott-e. Ezek után egy ciklust addig járatok, amíg az előzőekben említett változó hamis értékű. A ciklustörzsben pedig sorra kiértékelem a feltételeket, és ha valamelyik teljesül, a hozzá tartozó ágat lefuttatom, majd a lefutás-indikátort igazra állítom. Különben veszem a következő feltételt. Ha nincs több, kezdem elölről.
A feltétel lehet:
A beágyazott alternatívák kezelése a következő: először bekerül egy a fentebb leírthoz nagyon hasonló, de ciklus nélküli kód, ami a külsővel azonos lefutási indikátort használ, majd ennek vizsgálata adja a külső alternatíva tesztjét.
A változóval iterált alternatívák (replicated) esetén létrejön a változóval egy ciklus, aminek bennmaradási feltételében szerepel a lefutás-indikátor hamis értéke is. A teszt megvalósítása hasonló az eredeti változathoz, de minden bizonnyal szerepel benne az iterátorváltozóra vonatkozó hivatkozás is.
A következő táblázat mutatja az occam elemi típusainak megfelelőit (a “windows.h” felhasználásával):
| occam | C/C++ | occam | C/C++ |
| BOOL | BOOL | BYTE | BYTE |
| INT16 | SHORT | INT32 | LONG |
| INT64 | LONGLONG | INT (o INT32) | INT (o LONG) |
| REAL32 | FLOAT | REAL64 | DOUBLE |
Ezek a megfeleltetések egy az egyben használhatóak, mert bitméretük és belső ábrázolási technikájuk azonos. Egyetlen kivétel az INT64-LONGLONG pár, aminél a LONGLONG az x86 platformon lebegőpontos számként van ábrázolva, míg az INT64 – mint neve is mutatja – egész. Az ebből eredő kompatibilitási problémákra még nem dolgoztam ki megoldást, addig az ábrázolás miatt esetleges eltérésekre számítanunk kell. (A Windows NT más platformjain a LONGLONG natív 64 bites egész szám, és minden valószínűség szerint a rohamléptekben fejlődő x86 architektúrán a leendő 64bites NT-nek is natív típusa lesz.)
Az időzítők a standardnak megfelelően ’INT’ típusú értéket szolgáltatnak. Értékük szoros kapcsolatban áll a Windows ’GetTickCount’ függvényének visszatérési értékével. (Mivel csak Windows NT alatt akarjuk futtatni a programjainkat, alternatív megoldásként a regisztrációs adatbázis HKEY_PERFORMANCE_DATA kulcsa alatti a ’System Up Time’ számlálót is használhatnánk; az 8 byte-os, így körülfordulási ideje is nagyobb.)
Az időzítők kezelésében semmi speciális sincs, a futásidejű függvénykönyvtár megfelelő elemeit használják.
Az occam nyelvben külön operátorok vannak a “telítéses” és a túlcsordulásos műveletekre. Sajnos az előbbiek a C/C++ nyelvből hiányoznak. Így e műveletek megvalósítása csak körülményesen lehetséges. A jelenlegi változat ezeket még nem tartalmazza. Azonban ez az esetek többségében nem okoz problémát, hiszen az occam processzek érvénytelenné (invalid) válnak, ha az eredmény nem fér el az ábrázolási tartományban, és ez nem célunk. Kétségtelen ugyanakkor, hogy az ilyen hibák INMOS eszközökkel megfelelő fordítással felfedezhetők, itt ugyanakkor rejtve maradnak.
A valós értékek kerekítése alapértelmezésben a legközelebbi ábrázolható felé történik (például konstans értékeknél), de explicit típuskonverziók esetén ettől el kellhet térnünk (’TRUNC’ a ’ROUND’ helyett). Ekkor vagy saját függvénnyel valósítjuk meg az átalakítást, vagy – mint ahogy én is tettem – a lebegőpontos processzor kerekítési módját átállítva kényszerítjük a C/C++-t a konverzióra (cast). Ez a tesztek tanúsága szerint helyes eredményt ad, hacsak be nem kapcsoljuk a globális optimalizációt, amikor is a C/C++ fordítóprogram megfelelő intelligenciájával optimalizálhatja az átalakítást, hogy minél pontosabb eredményt szolgáltathasson (a lebegőpontos érték változatlan maradhat). Ez valójában a mi érdekünkben történik, de tartsuk szem előtt, a transzputer ilyen esetekben ettől eltérő eredményt szolgáltat.
2.5.6.9. További implementációs korlátok
A jelenlegi megvalósítás a következő kulcsszavakat nem támogatja:
| kulcsszó | hatás |
| PRI | figyelmeztető üzenet fordításkor, prioritás nélkülivel azonos kódot ad |
| PLACE | mivel hardver specifikus, fordításkor hibaüzenetet ad |
| PORT | mivel hardver specifikus, fordításkor hibaüzenetet ad |
A standard occam könyvtáraknak csupán egy része készült el, bővítésük az igényeknek megfelelően folyamatosan történik.
A tesztelés hatóköre mind a fordítás-, mind a futásidejű környezetre kiterjed(t). Akceptanciatesztre még nem került sor. Ez minden bizonnyal egybe fog esni az éles tanszéki alkalmazás bevezetésével.
A funkcionális tesztelés elsősorban unit és alrendszer szinten folyt/folyik. Igyekeztem/Igyekszem mindenhol regressziós tesztet végezni, azaz javítás esetén minden kapcsoló részletet ismét tesztnek alávetni. Az tesztelés és integráció iránya leginkább bottom-up (volt). Leggyakrabban black box vizsgálatot végeztem/végzek. Az új modulokat ekvivalencia-osztályokból vett mintákkal tesztel(t)em.
Ami a teljesítményteszteket illeti, az előfeldolgozó résszel nem volt probléma, azonban az elemző (sajnálatos módon) lassúnak bizonyult, mint erről már feljebb szóltam. A kódgenerátor pedig még érdemben nem tesztelhető.
Egy konkrét eredmény:
| forrás | előfeldolgozás | elemzés | fordítás |
| 165 sor (6,24 kB) | 1 sec. | 22 perc (!) | (nincs adat) |
Úgy gondolom, a projekt befejeztével a kitűzött feladatot maradéktalanul megoldom. Az a cél, hogy az Automatizálási Tanszék számára rendelkezésre álljon egy olyan occam fordítóprogram, amely nem a transzputeren fut, ezzel is segítve a Villamosmérnöki és Informatikai Kar hallgatóit az occam nyelv könnyebb elsajátításában, teljesülni látszik. Ugyan még néhány dolgon finomítani szükséges (vö. parser sebessége), de ez már a szoftver egészét tekintve részletkérdés.
A munkám során a legjelentősebb és a témához kapcsolódó (elsősorban transzputerrel, occammel, Prologgal foglalkozó) nyomtatott és elektronikus formában fellelhető irodalmat és szoftvereket igyekeztem megismerni. Ezáltal ma már tisztán látom az occam szerepét a programozási nyelvek Bábelében. Ezen kívül tovább tökéletesítettem jártasságomat Prologban és – mint arra a következő pontban példát is említek, – új területek meghódítására szeretném felhasználni.
Ami pedig a konkrét problémát, a fordítóprogramot illeti, világosan látszik, hogy nem ez az első próbálkozás a forrásnyelv elszakítására eredeti környezetétől. Azonban az általam fellelt, tervezési-megvalósítási avagy működési fázisban levő termékek egyike sem valósítja meg és/vagy nem is tervezi (legfeljebb ipari méretekben, pl.: http://nscp.upenn.edu/parallel/occam/projects/occam-for-all/case-for-support.html) a programfejlesztés további támogatását integrált fejlesztői környezetté bővítve az aktuális eszközt. Ezzel pedig “sikeresen” kizárva a jövő mérnök nemzedékét ezek tapasztalati úton történő megismerésétől. Én igyekeztem egy olyan célplatformot keresni, amely könnyebben elérhető, mint például a KRoC Sparc-ja, Alpha-ja és PowerPC-je, továbbá lehetőségeivel megfelel mind a célnak, mind a célfelhasználók elvárásainak. Úgy érzem, ez sikeres volt, és e tevékenységem végül is a szoftvermérnök-társadalmat fogja szolgálni.
A fentiekben leírt szoftver (elsősorban a rendelkezésre álló idő miatt) még korántsem teljes. Azonban miután elkészült, (szándékom szerint legalábbis) könnyen továbbfejleszthető az irodalomjegyzékben 3.-ként és 2.-ként feltűntetett leírásoknak megfelelő occam 2.1 ill. occam 3 nyelvű források feldolgozására.
A program jelenlegi állapotában pusztán egy fordító, amihez még célnyelvi eszközök kellenek, hogy futtatható állományokat kapjunk. Természetesen adódik a gondolat, hogy elkészüljön legalább egy olyan burok, amely megfelelően felparaméterezve a célnyelvi alkalmazásokat a felhasználó közreműködése nélkül, automatikusan futtatná a végeredmény előállítása érdekében.
Sőt, továbblépve, nem lenne lehetetlen a natív gépi kód generálása sem, azonban ennek jelenlegi megvalósítása lehetőségeimet meghaladta volna. Ez – megfelelő kódolási tudással – természetesen együtt járna a lefordított program hatékonyságának ugrásszerű növekedésével. Ennek belátásához vegyük figyelembe, hogy a C/C++ nyelvvel az occam bizonyos lehetőségei csak igen körülményesen valósíthatóak meg.
Ha pedig már a processzor számára közvetlenül érthető gépi utasításokat generálunk, nem okoz nehézséget ezt a tanszék transzputereire is kiterjeszteni. (Az eredeti ötlet egyébként ez volt, a debuggolási lehetőségek hiánya elfordított ettől és más irányban kezdtem el vizsgálódni.)
A bevezetés egy alpontjában felvetett két probléma megoldására is remek kiindulópontul szolgálhat ez a projekt:
Sőt, továbbmenve, már a fejlesztési szakaszban igen hatékony eszközöket adhatnánk a szoftveresek kezébe: grafikus felületen valamiféle mutató eszköz segítségével az egyes, fekete dobozként tekintett folyamatok kívülről látható jellemzőit egyszerűen adhatnánk meg, és vizuálisan rendkívül jól ellenőrizhető lenne. A “belső” kitöltéséhez pedig tiszta logikát, például Prologot használhatnánk. Hogy mi lenne ebben akkor még occam? Egyrészt az a szemléletmód, ahogyan a feladatokat egymással egyirányú csatornán szinkron módon kommunikáló, konkurensen futó elemi részekből, processzekből raknánk össze. Másrészt végül is a transzputer(ek)en futtatáshoz occam-ra fordítanánk. A fentieket mind magába foglaló környezet a legmodernebb szoftverfejlesztési eszközök egyike lehetne.
| [1] | Occam 2 Reference Manual, Prentice Hall International (UK) Ltd, 1988 |
| [2] | Geoff Barrett: occam3 reference manual, draft, INMOS Limited, March 31, 1992 (http://NSCP01.PHYSICS.UPENN.EDU/parallel/occam/documentation/) |
| [3] | occam 2.1 reference manual, SGS-THOMSON Microelectronics Limited, May 12, 1995 (http://NSCP01.PHYSICS.UPENN.EDU/parallel/occam/documentation/) |
| [4] | Szeredi Péter: Bevezetés a logikai programozásba, Jegyzetek a BME harmadéves informatikus hallgatói számára, Budapest, 1997 |
| [5] | SICStus Prolog (3#6) User’s Manual, Swedish Institute of Computer Science, November 1997 |
| [6] | dr. Bach Iván: Számítástechnikai nyelvészet, Műegyetemi Kiadó, 1997 |
| [7] | dr. László Zoltán: Programozás technológiája, Műegyetemi Kiadó, 1996 |
| [8] | Peter Van Roy: Can Logic
Programming Execute as Fast as Imperative Programming? pages
213-219: Appendix E Extended DCG notation: A tool for
applicative programming in Prolog; Extended DCG notation:
A tool for applicative programming in Prolog, User Manual,
Ph.D. in Computer Science, UC Berkeley, December 1990 (http://www.info.ucl.ac.be/people/PVR/Peter.thesis/Peter.thesis.html) |
| [9] | M. Ben-Ari: Principles of Concurrent and Distributed Programming, Prentice Hall International (UK) Ltd, 1990 |
| [10] | Parallel Processing, The Transputer and its Applications, Addison-Wesley, 1994 |
| [11] | Ronald S. Cok: Parallel Programs for the Transputer, Prentice-Hall, Inc., 1991 |
| [12] | Transputer Development System, Prentice Hall, 1990 |
| [13] | Fokt Attila: J2000 Prologban, Budapest, 1998 (html-fájlok) |
| [14] | The JANUS2000 Tool Set, (A szerző, Molnár Máté elérhető: e-mail: mate.molnar@bps.mts.dec.com, tel: (36-1) 458-5422) |
| [15] | JANUS2000. USER’S
GUIDE, pages 5-9, 27-28: The Y2KPARS program. The
Syntax Description; Appendix A. Built-in Terminals (A szerző, Molnár Máté elérhető: e-mail: mate.molnar@bps.mts.dec.com, tel: (36-1) 458-5422) |